Дакинг
Дакинг, если по простому - это уменьшение громкости оригинальной (в нашем случае японской) аудио-дороги в момент звучания русской озвучки.
Есть несколько вариаций дакинга, простые и более продвинутые. Рассмотрим их.
1 Классический (im4x)
В простом дакинге используется компрессор с функцией сайдчейна.


Для начала нужно сделать посыл из папки с озвучкой на дорогу с оригиналом в каналы 3/4 (это и есть сайдчейн) как на гифке.

На трек с оригиналом добавляем добавляем компрессор, в данном случае стандартный ReaComp, настраиваем как на скрине и слушаем результат. Предполагается что вы уже знаете за что отвечает каждый параметр компрессора.
Можно пойти дальше и использовать FabFilter Pro-C2 вместо стандартного.

Тут настройки чуть другие, обязательно выключаем AUTOGAIN и выбираем стиль Vocal,
в панеле SIDE CHAIN выбираем Ext, остальные параметры настраиваем на слух.
Мы можем чуть улучшить результат выкрутив ползунок STEREO LINK вправо (на скрине ниже), таким образом глушиться будет только Mid часть оригинала, а звуки и музыка по сторонам не будут. Мы как-бы впихиваем нашу озвучку в центр микса, а не поверх. Однако! в моментах с широкими по панораме эффектами, например реверберация, это не будет работать нормально, и нужно будет автоматизацией возвращать этот параметр в исходное положение. (пример ниже)




Важно!!
Не нужно сильно глушить оригинал, он должен быть слышен за русской озвучкой, но и не должен перебивать ее, найдите баланс.
2 С нейронкой UVR (im4x)
Системные требования:
ОС - Windows 10/11
Видеокарта - Nvidia минимум 4гб видеопамяти
Память - 16 гб
Диск - желательно ССД и файл подкачки добавить
Проц - Чем современнее - тем лучше. Если ЦП достаточно мощный, то и без видеокарты от зеленых можно обойтись, просто сильно дольше по времени будет.
-
Скачать и ознакомиться подробнее можно тут GitHub - Anjok07/ultimatevocalremovergui: GUI for a Vocal Remover that uses Deep Neural Networks.
-
Устанавливаем как предлагает установщик, ничего не меняем, иначе могут быть проблемы с работой.
-
Запускаем программу и сразу переходим в настройки (1) затем Download Center (2) Выбираем VR Arch и модель как на скрине (3), загружаем (4)

После многократного тестирования различных моделей, пришел к выводу, что на данный момент модель 8_HP2-UVR работает лучше остальных, в будущем возможно что то поменяется.
НАСТРОЙКА
(1) Выбираем исходный файл который нужно разделить. Должен быть в стерео или моно. Поддерживаются наверное все форматы, можно сразу указывать равку .mkv. (Можно выбрать сразу несколько файлов)
(2) Выбираем папку куда сохранить результат, обычно та же самая папка.
(3) В каком формате будет вывод WAV или FLAC - по желанию.
(4) Если видеокарта Nvidia то ставим галочку, если другая - убираем.
(5) Выбираем лучшую модель 8_HP2-UVR
(6) Запуск процесса, тут понятно.


Чем мощнее видеокарта тем быстрее процесс.
В настройках, во вкладке Additional Settings, можно выбрать битность аудио, если звук в BDRip 24 бита, желательно выбрать это в настройках, можно и для всех релизов делать 24 бита.

Для продолжительных аудио файлов, фильмов например, возможно придется предварительно нарезать аудио на несколько частей, или иметь овер много ОЗУ + видеопамяти, иначе процесс будет крашиться из-за недостатка ресурсов.
ВОКАЛ
В рабочей станции теперь вместо одного файла равки добавляем 3 файла - видео, инструментал, вокал.
(1) Инструментальный трек никак не трогаем на данном этапе.
(2) На треке с вокалом делаем сайдчейн компрессию, так же как и при обычном дакинге. (о моих настройках компрессии чуть позже)
(3) Алгоритмы естественно не идеальны, и поэтому очень часто в вокальный трек попадают различные эффекты (на скрине выделено оранжевым цветом). Чтобы дакинг не срабатывал в такие моменты, и не глушил эти эффекты, я привык автоматизацией отключать плагин (выделено зеленым ). Это конечно не обязательно, но так лучше звучит.

Более удачные примеры отключения дакинга:

**


ИНСТРУМЕНТАЛ
По ходу тайминга прислушиваемся к инструменталу. Т.к. давим мы только оригинальный вокал, то на инструментале, среди музыки и эффектов, иногда отчетливо будут проскакивать звуки из вокала. Чаще всего это резкие согласные звуки (К, Б, П, Т, С, Ц и прочие) оттого что они резкие, они хорошо привлекают к себе внимание. Отмечаем такие места маркерами, солируем инструментальный трек чтобы лучше разобрать есть ли косяк или нет.




Если в оригинале вокал сильно низкий, часть этих низов может попасть в инструментал. Звучит как низкий бубнеж в котором едва-ли можно что-то разобрать

Фиксится это разными способами, для меня самый удобный - редактирование спектра в iZotope RX.

В RX находим нужные фрагменты
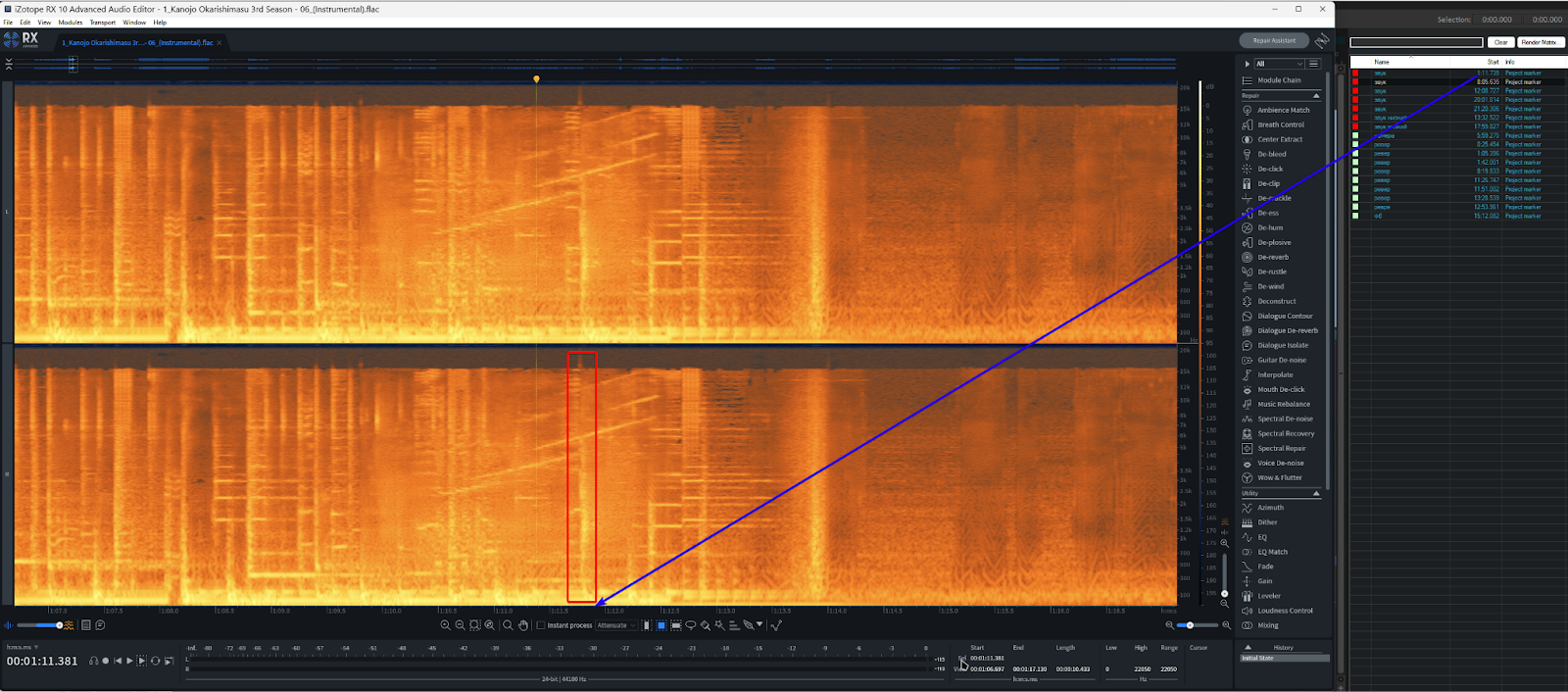
В нижней части ставим галочку на Instant process, режим Attenuate и нужный режим выделения.

Выделяем фрагмент

Лишний звук испарился 👍

Повторяем процедуру для оставшихся артефактов


Иногда одного выделения может не хватить, повторяем процедуру несколько раз, добиваясь приемлемого звучания в этом месте.
Выделять нужно только те частоты, в которых находятся артефакты, а не все подряд.

По окончании всех манипуляций, сохраняем и перезаписываем файл

Если работаете в рипере, он подхватит новый файл и перестроит пики.
До:

После:

Слушаем результат в полном миксе, и, удостоверившись что все хорошо, рендерим и собираем серию. Вы великолепны 🥳👍
Мои настройки компрессора:
за уровень подавления отвечает Range - чем больше уровень, тем сильнее подавление.
Оптимальные значения на мой слух от 10 до 12 дб
